An example driven guide to regular expressions
The problem
You have a string of text that needs to be checked to see if it fits a validation pattern or to extract information from it.
In the case of validation you might want to know if a given input is a valid currency amount like £100, so you can prompt the user to enter a valid amount before you process a transaction.
For parsing you might want to get the version of a users web browser given from a User Agent string like these:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172 Safari/537.22 Mozilla/5.0 (Windows NT 6.1; WOW64; rv:5.0) Gecko/20100101 Firefox/5.0 Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0
To solve both problems we either need to either split the text and manually check for conditions in our code or we can use a regular expression.
What is a regular expression?
Regular expressions are a DSL which consist of two parts, a target string and the regular expression itself. The regular expression part is kind of like the patterns you use to search for files with wildcards. They look very scary at first but you only need to know a few rules to get the most out of them.
Given a target string of 'Mississippi' and a regular expression of /s/ we would get a match back as the target string contains at least one 's'. Though this is a quite simple example, usually they use a number of regular expression features like: /^d\w[uiop](in|vi)[^a-f]*$/ which matches 'driving'.
How does it work?
A regular expression is made up of literal characters, metacharacters and escape sequences.
A literal is like in the Mississippi example above, the /m/ literally means this contains an 'm' anywhere in the target string.
A metacharacter is used within a regular expression for special characters that don't have a literal meaning, for example a caret sign indicates this regular expression must match from the start of the line. Meaning /^s/ would no longer match Mississippi but /^m/ would.
Finally, an escape sequence is used to convert a metacharacter into a literal for when the need arrises. For example the dollar sign '$' has a special meaning so to literally search for it we'd escape it by putting a slash at the front like /\$/.
Capture groups
The first metacharacter we'll get to know properly is the capture group, as this is what allows you to extract a substring of text from a target string.
Let's say we wanted to find the version of the IE web browser a visitor was using which has a target string of 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0'. In here we are looking for the '8.0' following the MSIE. A simple way to achieve this would be to do /MSIE (8.0)/
Boolean 'or'
If you wanted to search for one string or an alternative. You could do this with a pipe sign allowing you to match two different versions of IE: /MSIE (8.0|9.0)/
Matching any single character
Searching for just 8.0 or 9.0 is quite limiting though, so let's use the dot '.' metacharcter to search for any version number with a length of three characters with /MSIE (...)/
Iteration metacharacters
Matching on exactly three characters using the dot is working well for us here, but we know IE 10.0 is coming soon and many later versions after that. What we want is a variable amount of matching characters. To do this regular expressions allow us to put an iteration metacharacter right after a literal or other metacharacter to say how many times we'd like it to match.
Regular expressions give us curly brackets to do this. Say we expect exactly three occurrences of the previous pattern we could do: /MSIE (.{3})/
The curly brackets also allow us to use a range to match a minimum or maximum amount using /MSIE (.{3,4});/. In this example we've added the literal semi-colon to indicate the end of the version in the target string.
In we wanted to future proof to even larger version numbers of IE we could leave the second value blank: /MSIE (.{3,});/.
The regular expression creators realised this is quite a common task, so they made metacharacters to support the common ranges:
- ? : Zero or one {0,1}
- + : 1 or more {1,}
- * : Zero or more {0,}
The question mark is particularly useful when dealing with pluralization. So you could match a target string of 'game' or 'games' with /games?/.
Positioning
We've been looking for regular expressions that occur anywhere within a string so far. When you want your expression to match an entire line you use the $ and ^ signs. ^ means from the start of the line and $ means from the end of the line. This prevents your expression matching characters you don't want it to.
For example /^brown fox$/ matches 'brown fox' but not 'brown fox jumps away'.
Character classes
Up to now we've searched for literal matches or used the dot wildcard. Sometimes you want to search for a string that matches a list of possibilites. Square brackets allow you to do this /[01234556789]/.
Within a range the hypen, '-', becomes a metacharacter that allows you to specify a range. So the previous example can become /[0-9]/
As well as numbers you can do the same with letters with /[A-Z]/ for uppercase letters and /[a-z]/ for lower case.
These ranges can be combined to search for alpha numeric characters with /[A-Za-z0-9]+/
Finally, you can invert the selection by placing a caret at the start of the range to search for the opposite /[^0-9]/
Shorthand character classes
Just like with the range shorthands, the regular expression creators realised that character classes are a common occurance as well. To help with this they added some shorthand versions of popular tasks:
- \d : digits [0-9]
- \w : alpha numeric search for [0-9A-Za-z]
- \s : searches for spaces, tabs, and other whitespace
All of these letters can be made upper case to search for the opposite, just like the caret did previously with ranges. So \D means not a number.
Capture groups extended
If you don't want to capture the contents of a group you can put a question mark and a colon at the start of the group. This is useful when you need to use groups but don't care what their contents are. For example /the cost of the (?:grey|gray) sofa is £(d+)/ will handle the different spellings of the colour grey, but only capture the price.
If you'd like to add text into the capture group to make it readable, called a named group, you can use angle brackets within the group. For example to extract a date naming each part you could use /(?<month>d{1,2})/(?<day>d{1,2})/(?<year>d{4})/ on the target string 'Today's date is: 10/23/2012' to get 'month 10, day 23, year 2012'
You can also reuse a capture group using 1 to search for the same pattern again, this is called a backreference. For example with html tags you'd want to make sure that the closing tag matches exactly the same element name as the opening tag with /<(em|strong)>.*</(1)>/ which makes sure a </strong> or </em> matches it's opening tag.
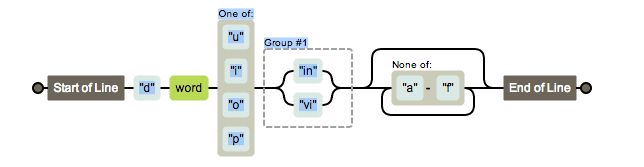
/^d\w[uiop](in|vi)[^a-f]*$/
Earlier on I said this regular expression can match the target string 'driving'.
Let's break down what's happening here. We've got positional anchors with the ^ and $ that let us know the entire contents of the string are within the regular expression. Let's remove them to give us: dw[uiop](in|vi)[^a-f]*
The first letter is a literal 'd'. Followed by a single alphanumeric 'w'. Then we have a range of possible single characters [uiop], followed by a boolean or '(in|vi)' and finally a range between 0 or infinite characters that doesn't contain any letters between a-f. One word which matches these conditions is 'driving'.
If you come across such crazy regular expressions I'd encourage you to put them into Regexper which will explain them for you. For this expression Regexper gives us this diagram:
Why would someone make this regular expression?
I've given you a crash course in what you need to know to solve most problems with regular expressions. Now see if you can put your knowledge to test by solving this regular expression crossword puzzle.